How we migrated 30,000 blogs & 400,000 users across an ocean with zero downtime

Some time in May 2013, a handful of fearless (ha) developers sat down to work on the very first implementation Ghost(Pro), the official hosted platform for Ghost. The aim was to ship it as fast as humanly possible.
They succeeded. On the 14th of October 2013 Ghost(Pro) started serving blogs for Kickstarter backers from a datacenter in England.
I remember this day quite well. It was my first official day at Ghost.
This first version of Ghost's hosted platform was the foundation of our success as a business. It enabled us to generate revenue beyond the initial crowd funding, grow the team, and continue working on the project for years to come.
Fast forward one year into the future, and things have changed - I've spent a lot of time working on Ghost's JSON API, reviewed and tested hundreds of pull requests and started to take over management of the Ghost(Pro) infrastructure.
It's the last quarter of 2014 and we're now serving about 100 million requests per month from tens-of-thousands of blogs. We realise that the existing system is about to becoming a bottleneck for the further development of Ghost itself. The quick shortcuts that allowed us to ship fast are going to become real problems in the next year, and scaling our application servers means kicking off a 2-month hardware purchasing and deployment process.
In short: We were just about to outgrow our infrastructure, and we needed to react before we hit the wall.
Operating Ghost(Pro) for over a year showed us what we needed to do better and where we could improve our service. Our wishlist for the new infrastructure was quite long and included requirements like being able to set up new servers within minutes, satisfy our hunger for RAM, offer great customer support, and migrate our existing software without a huge refactor.
After talking with the team at DigitalOcean and ticking off most of the boxes on our wishlist, we'd come up with an agreement to work together which would benefit everyone.
And so began the great migration.
With plenty of refactoring already needed for our existing stack, there was a lot to juggle when the migration project began. Trying to do refactoring, improvements, and migration at the same time would have been an unmitigated recipe for disaster.
Instead, we divided up the work:
- First migration
- Then refactoring
- and finally: improvements.
But how do you migrate a live service with constantly changing data between servers? Initially we thought we'd switch off all our sites, make sure we have the latest changes, copy the data to the new servers and switch it all back on again.
Which, in the grand scheme of things, fell somewhere on the spectrum between cute and hilariously naive.
Inventory
The first step was to create an inventory of what was currently running on our servers.
Every system administrator knows what software is running in their datacenter, but I don't know anyone who could replicate the configuration of multiple servers by heart. Including me. So we needed to gather all of the important (and maybe unimportant) information about our servers.
We introduced a configuration management system to keep track of installed software packages, firewall settings and configuration itself. Our weapon of choice here is Saltstack. The added benefit of doing this now is that we won't ever need to dig through the servers to find out what our configuration looks like in the future.
I don’t have particularly strong feelings one way or the other when it comes to configuration management tools. It needs to get the job done and blend in with our overall philosophy of not being overloaded. Saltstack does that for us and it hasn’t let us down. The infrastructure repository contains about 150 salt state files and holds all the information needed (without passwords, of course) to set up Ghost(Pro).
Although setting up Saltstack took some time, it's already shown its power. It took about a month to set up the first complete clone of the whole network. The second iteration only took one week. When I started to do the third installation of what would become our new hosted platform it only took me 2 days to have 20 servers deployed and ready.
Formalising our setup also surfaced a lot of small parts that need improvement which I added to our list of refactoring tasks.
Another thing we found to speed up managing our infrastructure was Salt-cloud. It proved to be a really important tool for starting, stopping and deploying servers within minutes. It integrates closely with DigitalOcean's API and allows us to manage the infrastructure from the command line.
Ghost(Pro) Internals
Here is a snapshot of what the Ghost(Pro) server topology now looks like. Below you'll find a short overview of what each part is responsible for.
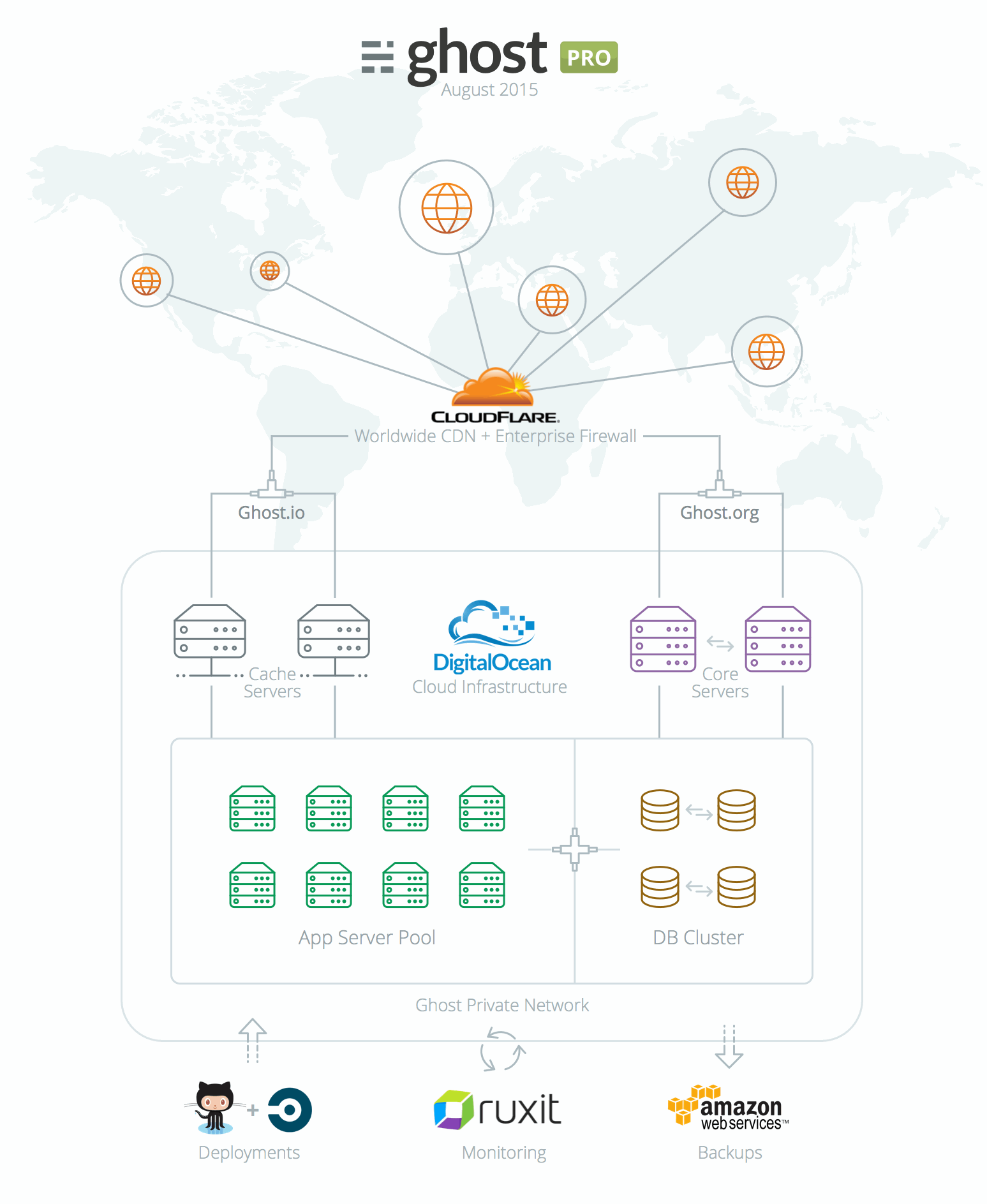
- CloudFlare provides a Content Delivery Network (CDN), Domain Name Services (DNS), caching and protection from malicious requests.
- Core Servers host ghost.org and are responsible for user and payment management.
- Cache Servers are used to further speed up responses and direct requests to the correct blogs.
- App Server Pool consists of many App Servers which run your Ghost blog.
- DB Cluster is a cluster of MySql databases that hold your blog data.
- Github handles our source code management.
- Ruxit is responsible for monitoring Ghost(Pro) infrastructure.
- Amazon S3 is used to store encrypted, off-site backups.
Once a service moves to the cloud, it requires a whole new level of security. We were used to having our servers in a datacenter where only our public facing services were available on the internet. Access to all other servers required access to our well protected internal network using VPN.
With the move to the cloud that suddenly changed.
Private Network
All servers now have public IP addresses and are reachable for everyone on the internet. This is terrifying, but thankfully it's something that can be solved with the right tools on hand.
The servers are locked down with firewalls. After seeing that internal traffic was not private, DigitalOcean suggested we use tinc to keep internal traffic secure. tinc is a VPN daemon that creates an encrypted mesh network between different hosts on the internet. We use it to encrypt all internal traffic that is sent between our servers.
When downtime isn't an option
After analysing our existing data it dawned on me that the initial idea of doing the migration offline wouldn't work. There are about 500 GB of data stored in different databases on Ghost(Pro). This roughly translates to 6 hours of downtime while the data is backed up, transferred to the new servers and restored to the databases. Even worse, a single error in this process could double the downtime.
We needed an alternative plan to migrate our service without taking it offline for several hours.
Replication to the rescue!
First the databases were replicated to the new system in a master/slave setup. This means that the production system replicates to the cloud system but changes in the cloud are not replicated back.
Using this setup we were able to do load testing and see if the new system behaved equivalently to our old servers. After successful tests the databases on the new system were reset and replication as master/master was activated.
Now it was getting serious. Replication as master/master means that all changes are replicated in both directions. This setup would allow us to switch the service to the new servers and if anything went wrong we could switch back to the old servers since all changes that were made would be in-sync on both systems.
In addition to the increased safety, the migration was now reduced to switching the DNS entries to point to the new servers which already had the data. Updating DNS entries is always problematic because you have to wait for DNS to propagate. If done wrong the DNS propagation could take hours and users would randomly hit the old or the new system. We use CloudFlare to manage our DNS entries which allows realtime updates and reduces the hassle of switching to a new server to submitting a webform.
Migration Day
The moment of truth had come. I had been working on this project for 2 months by now and everything was prepared for the switchover. Everything was set up, final tests were done, and the databases were happily replicating all changes to the new system.
The last step was to update the DNS entries.
First ghost.org... Done!
Then ghost.io... Done!
Anticlimactic? Definitely. Which is the best possible outcome.
Empty caches caused some timeouts while serving blogs for a few hours after the migration. However, Ghost.org was not down at all and one customer even started the sign up process for Ghost(Pro) on the old system and finished the checkout process on the new system!
Keep watching dev.ghost.org for posts about improvements to Ghost(Pro) and how we use Saltstack, salt-cloud, tinc or MySQL. Drop me a line in the comments if you have any questions or thoughts!

